








Google DeepMind tərəfindən hazırlanmış FACTS Benchmark Suite testləri süni intellekt sistemlərinin real həyatda verdiyi cavabların etibarlılıq səviyyəsini ölçmək məqsədi daşıyır.
Bu testlər məlumat əsaslı suallar, uzun mətnlərin təhlili, internet mənbələrinə əsaslanan cavablar və vizual interpretasiya kimi müxtəlif sahələri əhatə edir. Məqsəd süni intellekt modellərinin yalnız axıcı cavab vermə qabiliyyətini deyil, faktiki düzgünlük səviyyəsini qiymətləndirməkdir.
Testlərin nəticələri göstərir ki, ən yüksək performanslı süni intellekt modelləri belə maksimum 69% dəqiqlik səviyyəsinə çata bilir. Bu isə o deməkdir ki, AI sistemlərinin verdiyi cavabların təxminən üçdə biri yanlış, natamam və ya istifadəçini çaşdıra biləcək məlumatlardan ibarət ola bilər. Cavabların inandırıcı və səlis səslənməsi onların hər zaman doğru olduğu anlamına gəlmir.
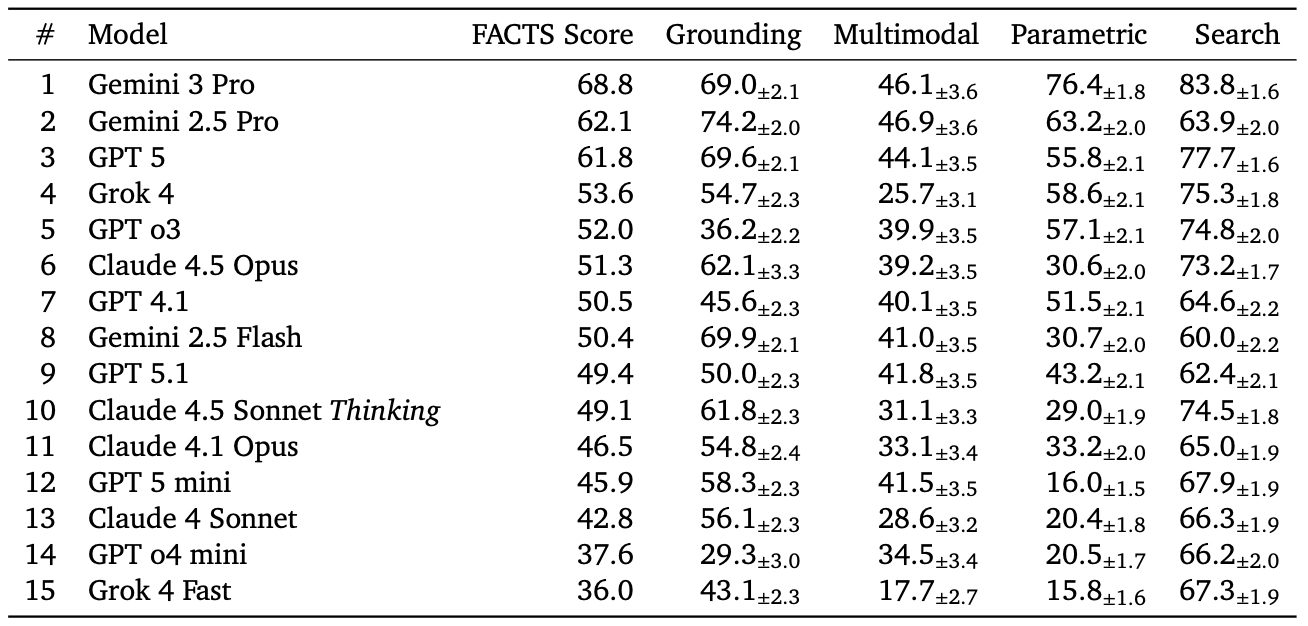
Bu nəticələr xüsusilə səhiyyə, hüquq və maliyyə kimi yüksək risk daşıyan sahələr üçün ciddi xəbərdarlıq hesab olunur. Bu sahələrdə verilən yanlış və ya qeyri-dəqiq məlumatlar insan sağlamlığına, hüquqi qərarlara və maliyyə təhlükəsizliyinə birbaşa təsir göstərə bilər. DeepMind mütəxəssisləri vurğulayır ki, süni intellekt alətləri qərarverici mexanizm kimi deyil, dəstək vasitəsi kimi istifadə edilməlidir.
Araşdırma bir daha göstərir ki, süni intellekt texnologiyaları sürətlə inkişaf etsə də, onların etibarlılığı hələ də insan nəzarəti və əlavə yoxlama mexanizmləri olmadan kifayət qədər təhlükəsiz deyil. Buna görə də AI sistemlərinin kritik sahələrdə istifadəsi zamanı ehtiyatlı yanaşma və məsuliyyətli tətbiq vacib olaraq qalır.
Daha çox
Texnologiya
kateqoriyasından






